Projet: Contrôle optimal par recherche arborescente et algorithme UCTMatthieu Guerquin-Kern1Le 16 janvier 2007 |
Abstract: Disposant d'un modèle de la dynamique d'un processus, on peut envisager d'aborder la résolution du problème de contrôle par une recherche arborescente. L'arbre est alors construit à partir de diverses simulations Monte-Carlo. Dans ce travail, l'application visée est le contrôle du processus de digestion anaérobie de matière polluante organique par une colonie de bactéries. Nous disposons d'un modèle du processus, mais il est relativement complexe. Notre arbre de recherche arborescent se construit donc dans un espace d'états à grandes dimensions, ce qui rend rapidement incommensurable le nombre de calculs à effectuer. C'est pourquoi nous envisageons l'utilisation du récent algorithme, UCT, qui, résolvant le fameux dilemme exploration-exploitation, optimise le parcours de l'arbre dans un temps donné.
|
|
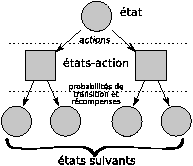
Alors, la valeur Vx à attribuer à un noeud x de l'arbre serait le maximum des valeurs V(x,a) attribuées aux états-actions (x,a) lui étant liés: Vx=maxaV(x,a). Ces valeurs-ci étant elles-mêmes estimées en moyennant les récompenses r obtenues dans la transition du noeud état-action vers le noeud état suivant et en l'ajoutant à la valeur des états suivants x': V(x,a)=E(r+Vx'|a). On attribue la valeur 0 aux états ”feuilles” de l'arbre et par descente vers la racine, on attribue les valeurs à chaque état. Ainsi, à l'état racine, l'action choisie sera celle pour laquelle la valeur du couple état-action est la plus grande.
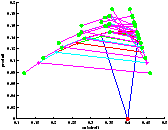
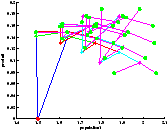
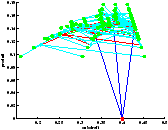
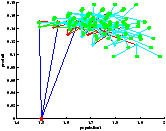
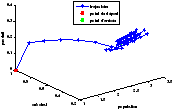
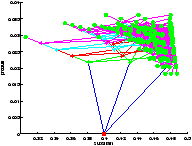
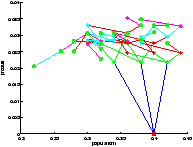
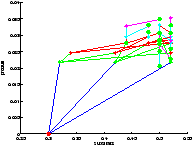
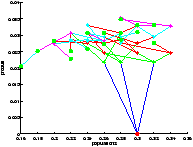
On a représenté le point de départ en rouge et les feuilles sont représentées par un point vert.
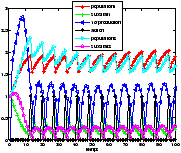
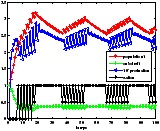
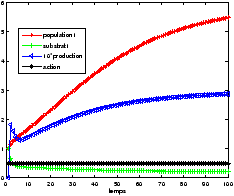
On remarque qu'au départ, l'action est nulle. La population bactérienne grandit et consomme l'excès de substrat. C'est le comportement du système lorsqu'il est laissé au repos (pas d'alimentation en substrat). Puis la population se régule et on a convergence de l'état vers un régime permanent.
D'ailleurs, remarquons que, le modèle 2.2.14Modèle simplifiésubsubsection.2.2.1 étant relativement simple, on pourrait prédire la valeur constante à donner à l'action pour maximiser la production. Dès lors, notre problématique perd beaucoup de son intérêt.
On constate sur la figure ?? que l'on a bien quantification des états. Il faut prendre garde à la lecture de l'arbre car on n'a pas échantillonné le produit, ce qui fait que des états confondus au sens de la quantification peuvent paraître sur une ordonnée différente. Leurs abscisses sont par contre les mêmes.
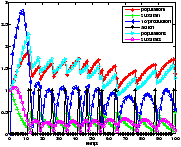
Le résultat du contrôle est présenté figure 712Résultats obtenus avec le modèle <A HREF="#simple">2.2.14Modèle simplifiésubsubsection.2.2.1</A>figure.7. On constate que la valeur moyenne de la production dans le régime permanent est plus élevée. On a donc su avec cette méthode d'exploration, contrôler notre système de manière plus performante. C'est étrange car la profondeur d'exploration est quasiment la même que pour l'expérience réalisée avec le modèle 2.2.14Modèle simplifiésubsubsection.2.2.1, présentée figure ??. En fait, on montre ici que pour la profondeur d'exploration considérée l'idée de choisir la première action de la trajectoire qui maximise la somme actualisée des récompenses est loin de l'action optimale.
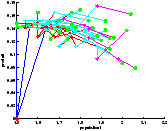
On a bien vu avec le temps de calcul que l'exploration par UCT n'était pas plus performante (en termes de rapidité) pour cette profondeur d'exploration. Cependant, on constate qu'elle parvient à visiter les états les plus intéressants si l'on accorde un nombre de trajectoires suffisant.
Là encore, le résultat est étonnement meilleur en utilisant l'UCT.
| 1 % Ce script est le script principal du projet. Avec lui, on peut simuler le 2 % contrle du racteur. Les paramtres rgler sont: 3 % 1) l'tat initial via la dclaration du noeud, qui dtermine quel modle 4 % du processus utiliser par la suite. 5 % 2) le nombre d'actions M. 6 % 3) la profondeur d'exploration. 7 % 4) le nombre d'itrations de l'algorithme. 8 % 5) le coefficient d'actualisation. 9 % 6) l'algorithme utiliser pour calculer l'arbre. 10 % 11 % A la fin, on affiche la trajectoire suivie au cours du temps dans 12 % l'espace d'tat. 13 14 15 M = 2; % nombre d'actions 16 p = 8; % profondeur 17 nbr = 100; % itrations 18 gamma = 0.9; % coefficient d'actualisation 19 20 % structure de chaque noeud + intialisation 21 %noeud = declaration_noeud([1 1 0],M); %modele1 22 %noeud = declaration_noeud([0.4 6 0],M); %modele1[1 1 0] 23 noeud = declaration_noeud([1 1 1 1 0],M); %modele2 24 25 % Modle utiliser 26 modele = @modele1; 27 if length([fieldnames(noeud.etat)])>3 28 modele = @modele2; 29 end 30 31 % Dbut de la simulation 32 data = []; 33 action = []; 34 for i = 1:nbr 35 % sauvegarde de la trajectoire 36 data = [data noeud.etat]; 37 % Calcul de l'arbre 38 arbre = exploration(noeud,[1:M],gamma,p,M); 39 %arbre = UCT(noeud,[1:M],gamma,p,M); 40 41 % Choix de l'action optimale 42 [somme_act sequence] = best_somme_act(arbre); 43 44 45 % Action constante 46 %sequence(1) = 2; 47 %arbre(1) = noeud; 48 49 50 51 action = [action sequence(1)]; 52 % calcul de l'tat suivant 53 noeud.etat = modele(arbre(1).etat,sequence(1),M); 54 end 55 56 %%%%%%%%%%%%%%%%%%%%%%%%%%% 57 % Affichage des rsultats 58 if length([fieldnames(noeud.etat)])<4 59 figure(1); 60 plot3([data.population1],[data.substrat1],[data.produit],'b*-'); 61 xlabel('population');ylabel('substrat');zlabel('produit'); 62 hold on; 63 h = plot3([data(1).population1],[data(1).substrat1],[data(1).produit],'r.'); 64 set(h, 'MarkerSize', 25); 65 h = plot3([data(end).population1],[data(end).substrat1],[data(end).produit],'g.'); 66 set(h, 'MarkerSize', 25); 67 hold off; 68 legend('trajectoire','point de dpart','point d''arrive',0); 69 end 70 71 figure(2); 72 x = 1:length([data.population1]); 73 plot(x,[data.population1],'r-*');hold on; 74 plot(x,[data.substrat1],'g-+'); 75 plot(x,10*[data.produit],'b-<'); 76 plot(x,[action-1]/(M-1),'k-*'); 77 if length([fieldnames(noeud.etat)])>3 78 plot(x,[data.population2],'c->'); 79 plot(x,[data.substrat2],'m-o'); 80 legend('population1','substrat1','10*production','action','population2','substrat2',0); 81 else 82 legend('population1','substrat1','10*production','action',0); 83 end 84 hold off 85 xlabel('temps'); |
| 1 function arborescence(etatinit,M,p) 2 % Cette fonction sert lancer l'affichage d'un arbre partir d'un tat 3 % initial. 4 % M: nombre d'actions 5 % p: profondeur de l'arbre 6 % etatinit: tat initial: [sub1 pop1 prod] ou [sub1 pop1 sub2 pop2 prod] 7 8 % arborescence([0.32,0.4,0.02],4,3) 9 % arborescence([0.36,0.35,0.15,0.16,2e-3],4,3) 10 11 % structure de chaque noeud 12 noeud = declaration_noeud(etatinit,M); 13 14 % Calcul de l'arbre 15 tic;arbre = exploration(noeud,[1:M],0.9,p,M);toc 16 %tic;arbre = UCT(noeud,[1:M],1.2,p,M);toc 17 18 length(arbre) 19 20 % Affichage 21 plot_arbre(arbre); |
| 1 function arbre = exploration(noeud,actions,gamma,p,M) 2 % Explore, de manire nave, l'arbre des tats possibles partir de 3 % 'noeud' et en suivant les M actions, en s'arrtant une profondeur p. 4 % La somme des rcompenses est actualise avec le coefficient gamma. 5 6 arbre = [noeud]; 7 % Quel modle utiliser? 8 modele = @modele1; 9 if length([fieldnames(noeud.etat)])>3 10 modele = @modele2; 11 end 12 13 for i = 1:p %pour chaque profondeur 14 for x = search_depth(arbre,i-1) %pour chaque noeud la profondeur inf 15 for a = actions % pour chaque action 16 % calcul du nouvel tat 17 noeud.etat = modele(arbre(x).etat,a,M); 18 % mise jour des donnes 19 noeud.profondeur = i; 20 noeud.parent = x; 21 noeud.suivant = []; 22 arbre(x).somme_act(a) = arbre(x).somme_act(a)+gamma^(i-1)*noeud.etat.produit; 23 noeud.somme_act(:) = arbre(x).somme_act(a); 24 arbre(x).suivant(a) = length(arbre)+1; 25 arbre = [arbre noeud]; 26 end 27 end 28 end |
| 1 function arbre = UCT(noeud,actions,gamma,p,M) 2 % Explore, en utilisant l'algorithme UCT, l'arbre des tats possibles 3 % partir de 'noeud' et en suivant les M actions. Les rcompenses sont 4 % actualises avec le coefficient gamma. L'arbre va jusqu' la profondeur 5 % maximale p. 6 % 7 % Le nombre de trajectoires lances (timeout), 8 % le facteur de proportionnalit de la probabilit d'arrt, 9 % et le facteur de proportionnalit du biais sont ajuster ci dessous. 10 11 12 timeout = 60; 13 coeff_stop = 0.7; 14 coeff_biais = 0.1; 15 16 arbre = [noeud]; 17 % Quel modle utiliser? 18 modele = @modele1; 19 if length([fieldnames(noeud.etat)])>3 20 modele = @modele2; 21 end 22 23 for t = 1:timeout 24 %lancement d'une trajectoire partir de l'tat initial 25 arret = 0; 26 x = 1; % indice du noeud courant 27 arbre(x).compteur_etat = arbre(x).compteur_etat+1; 28 while ~arret % tant qu'il n'y a pas de condition d'arret 29 % choix de l'action 30 %arbre(x).somme_act(:)+bias_term(arbre(x)) 31 valeur = estimate_value(arbre,x); 32 biais = bias_term(arbre(x),coeff_biais); 33 [tmp a] = max(valeur(:)+biais(:)); 34 test = find((valeur(:)+biais(:))==tmp); 35 if length(test)>1 36 a = test(round((length(test)-1)*rand(1))+1); 37 end 38 % calcul du nouvel tat chantillonn si besoin 39 if (arbre(x).suivant(a)==0) %si suivant pas encore visit 40 % on le calcule 41 noeud.etat = echantillonnage(modele(arbre(x).etat,a,M)); 42 noeud.profondeur = arbre(x).profondeur+1; 43 noeud.parent = x; 44 % on vrifie si cet tat existe dj dans l'arbre 45 y = search_depth(arbre,noeud.profondeur); 46 if (length(y)~=0) 47 visited = find(egalite_etat([arbre(y).etat],noeud.etat)); 48 visited = y(visited); 49 else 50 visited =[]; 51 end 52 if (length(visited)~=0) % Si l'tat est dj dans l'arbre 53 %%%%%%%%% 54 % CAS 1 55 %on actualise les somme_acts et le parent du noeud 56 arbre(x).somme_act(a) = arbre(x).somme_act(a)+gamma^(arbre(x).profondeur-1)*arbre(visited).etat.produit; 57 % Changement du parent de l'tat suivant? 58 ind = arbre(visited).parent; 59 % C'est une question de somme actualise ! 60 if arbre(ind).somme_act(find([arbre(ind).suivant]==visited))<arbre(x).somme_act(a) 61 arbre(visited).parent = x; %changement de parent 62 arbre(visited).somme_act(:)=arbre(x).somme_act(a); %et de somme_act 63 end 64 arbre(x).suivant(a) = visited; 65 else %si l'tat suivant n'est pas dans l'arbre 66 %%%%%%%%%% 67 % CAS 3 68 arbre = [arbre noeud];% on l'y ajoute 69 arbre(x).somme_act(a) = arbre(x).somme_act(a)+gamma^(arbre(x).profondeur-1)*noeud.etat.produit; 70 arbre(x).suivant(a) = length(arbre); 71 arbre(end).somme_act(:) = arbre(x).somme_act(a); 72 end 73 else % si l'tat suivant est dj visit 74 %%%%%%%%%% 75 % CAS 2 76 end 77 %on actualise les compteurs et le parent du noeud 78 arbre(arbre(x).suivant(a)).compteur_etat=arbre(arbre(x).suivant(a)).compteur_etat+1; 79 arbre(x).compteur_etatactions(a)=arbre(x).compteur_etatactions(a)+1; 80 81 % Arrte-t-on l la trajectoire? 82 if (arbre(x).profondeur == p-1)|(rand(1)<coeff_stop/(1+0.5*arbre(x).compteur_etat)) 83 arret==1; 84 break; 85 end 86 x = arbre(x).suivant(a); 87 end 88 end 89 90 function bool = egalite_etat(etat1,etat2) 91 % teste l'galit de deux tats 92 93 if nargin < 2 94 bool = 0; 95 else 96 bool = ([etat1(:).population1]==etat2.population1).*([etat1(:).substrat1]==etat2.substrat1); 97 if length([fieldnames(etat1(1))])>3 98 bool = bool.*([etat1(:).population2]==etat2.population2).*([etat1(:).substrat2]==etat2.substrat2); 99 end 100 end 101 102 function C = bias_term(noeud,coeff_biais) 103 % Calcule le biais a partir des nombres de visites de l'tat et de ses 104 % tat-action 105 106 C = 2*coeff_biais*sqrt(log(noeud.compteur_etatactions(:)+1.01)./(noeud.compteur_etatactions(:)+0.01)); |
| 1 function etat_suiv = modele1(etat,action,M) 2 % Calcule l'tat suivant en utilisant le modle de connaissances et 3 % l'action choisie. (M sert normaliser l'action entre 0 et 1) 4 5 % Dfinition des paramtres 6 alpha = 0.1; 7 k1 = 1; 8 k2 = 2; 9 k3 = 2; 10 c1 = 1; 11 c2 = 3; 12 c3 = 8; 13 Sin = 0.5; 14 etat_suiv = etat; 15 action = (action-1)/(M-1); 16 tau = 1; 17 18 etat_suiv.substrat1 = etat.substrat1 +tau*(action*(Sin - etat.substrat1)-k1*etat.population1*c1*etat.substrat1/(c2*etat.substrat1^2+c3)); 19 if etat_suiv.substrat1<0 20 etat_suiv.substrat1=0; 21 end 22 etat_suiv.population1 = etat.population1 +tau*(-alpha*action*etat.population1+k2*etat.population1*c1*etat.substrat1/(c2*etat.substrat1^2+c3)); 23 if etat_suiv.population1<0 24 etat_suiv.population1=0; 25 end 26 etat_suiv.produit = k3*etat.population1*c1*etat.substrat1/(c2*etat.substrat1^2+c3); |
| 1 function etat_suiv = modele2(etat,action,M) 2 % Calcule l'tat suivant en utilisant le modle de connaissances 2 et 3 % l'action choisie. (M sert normaliser l'action entre 0 et 1) 4 5 % Dfinition des paramtres 6 alpha = 0.2; 7 k1 = 1; 8 k2 = 2; 9 k3 = 2; 10 k4 = 2; 11 c1 = 1; 12 c2 = 8; 13 c3 = 1; 14 c4 = 3; 15 c5 = 8; 16 S1in = 0.5; 17 S2in = 0.1; 18 etat_suiv = etat; 19 action = (action-1)/(M-1); 20 tau = 1; 21 22 etat_suiv.substrat1 = etat.substrat1 +tau*(action*(S1in - etat.substrat1)-k1*etat.population1*c1*etat.substrat1/(c2+etat.substrat1)); 23 if etat_suiv.substrat1<0 24 etat_suiv.substrat1=0; 25 end 26 etat_suiv.population1 = etat.population1 +tau*(-alpha*action*etat.population1+etat.population1*c1*etat.substrat1/(c2+etat.substrat1)); 27 if etat_suiv.population1<0 28 etat_suiv.population1=0; 29 end 30 etat_suiv.substrat2 = etat.substrat2 +tau*(action*(S2in - etat.substrat2)+k2*etat.population1*c1*etat.substrat1/(c2+etat.substrat1)-k3*etat.population2*c3*etat.substrat2/(c4*etat.substrat2^2+c5)); 31 if etat_suiv.substrat2<0 32 etat_suiv.substrat2=0; 33 end 34 etat_suiv.population2 = etat.population2 +tau*(-alpha*action*etat.population2+etat.population2*c3*etat.substrat2/(c4*etat.substrat2^2+c5)); 35 if etat_suiv.population2<0 36 etat_suiv.population2=0; 37 end 38 etat_suiv.produit = k4*etat.population2*c3*etat.substrat2/(c4*etat.substrat2^2+c5); |
| 1 function noeud = declaration_noeud(etatinit,M) 2 % Fonction permettant de dclarer un noeud pour l'arbre en l'initialisant 3 % l'tat dfinit par 'etatinit'. 4 5 if length(etatinit)==3 6 noeud.etat = struct('substrat1',etatinit(1),'population1',etatinit(2),'produit',etatinit(3)); 7 else 8 noeud.etat = struct('substrat1',etatinit(1),'population1',etatinit(2),'substrat2',etatinit(3),'population2',etatinit(4),'produit',etatinit(5)); 9 end 10 noeud.profondeur = 0; 11 noeud.parent = [0]; %indice du parent 12 noeud.suivant = [zeros(1,M)]; %indice des enfants selon l'action 13 noeud.somme_act = [zeros(1,M)]; %somme actualise des rcompenses associe chaque action 14 noeud.compteur_etat = 0; %initialisation du compteur de l'tat 15 noeud.compteur_etatactions = [zeros(1,M)]; %initialisation des compteurs |
| 1 function etat = echantillonnage(etat) 2 % fonction ralisant l'chantillonnage des tats avec les pas ci-dessous 3 4 pas_pop = 0.02; 5 pas_sub = 0.02; 6 7 etat.substrat1 = pas_sub*round(etat.substrat1/pas_sub); 8 etat.population1 = pas_pop*round(etat.population1/pas_pop); 9 if length([fieldnames(etat)])>3 10 etat.substrat2 = pas_sub*round(etat.substrat2/pas_sub); 11 etat.population2 = pas_pop*round(etat.population2/pas_pop); 12 end |
| 1 function plot_arbre(arbre) 2 % Fonction qui permet de reprsenter un arbre dans l'espace d'tat 3 4 close all; 5 6 racine = arbre(1); 7 M = size(racine.somme_act); %nombre d'actions 8 p = max([arbre.profondeur]); %profondeur de l'arbre 9 etats = [fieldnames(racine.etat)]; 10 n = length(etats); 11 color = ['b' 'g' 'r' 'c' 'm' 'y' 'k']; 12 13 for i = 1:p 14 ind = search_depth(arbre,i); 15 for j = ind 16 col = color(mod(getfield(arbre(j),'profondeur')-1,length(color))+1); 17 for fig = 1:n-1 18 figure(fig); 19 hold on; 20 nom = char(etats(fig)); 21 prod = char(etats(end)); 22 plot([getfield(arbre(arbre(j).parent).etat,nom) getfield(arbre(j).etat,nom)],[getfield(arbre(arbre(j).parent).etat,prod) getfield(arbre(j).etat,prod)],[col '-*']); 23 hold off; 24 end 25 end 26 end 27 for fig = 1:n-1 28 figure(fig) 29 hold on; 30 h = plot([getfield(arbre(1).etat,char(etats(fig)))],[getfield(arbre(1).etat,char(etats(end)))],'r.'); 31 set(h, 'MarkerSize', 25); 32 ind = search_leaves(arbre); 33 for i = ind 34 h = plot([getfield(arbre(i).etat,char(etats(fig)))],[getfield(arbre(i).etat,char(etats(end)))],'g.'); 35 set(h, 'MarkerSize', 25); 36 end 37 hold off; 38 xlabel(char(etats(fig))); 39 ylabel(char(etats(end))); 40 end |
| 1 function [somme_act sequence] = best_somme_act(arbre) 2 % Fonction qui cherche le noeud parmis les feuilles de l'arbre qui possde 3 % la plus grande somme actualis et retourne la suence d'actions qui 4 % mnent ce noeud ainsi que sa somme actualise. 5 6 ind = search_leaves(arbre); 7 a=[arbre(ind).somme_act]; 8 b=a(1:length(arbre(1).somme_act):end); 9 [somme_act x] = max(b); 10 sequence = []; 11 ind = ind(x); 12 for i=1:arbre(ind).profondeur 13 ind2 = arbre(ind).parent; 14 sequence = [find([arbre(ind2).suivant]==ind) sequence]; 15 ind = ind2; 16 end |
| 1 function valeur = estimate_value(arbre,ind_noeud) 2 % Fonction rcursive qui estime la valeur d'un noeud dans l'arbre en 3 % cherchant parmi les feuilles qui en sont issues la somme actualise 4 % maximale. 5 6 nbr = length(ind_noeud); 7 if nbr>1 8 for i=1:nbr 9 valeur(i) = estimate_value(arbre,ind_noeud(i)); 10 end 11 end 12 13 s = sum([arbre(ind_noeud).suivant]); 14 15 if (s==0) 16 valeur = arbre(ind_noeud).somme_act; 17 else 18 i = find(arbre(ind_noeud).suivant(:)~=0); 19 seq = []; 20 for j = 1:length(i) 21 seq = [seq estimate_value(arbre,arbre(ind_noeud).suivant(i(j)))]; 22 end 23 valeur = max(seq); 24 end |
| 1 function ind = search_depth(arbre,p) 2 % retourne les indices des noeuds de l'arbre qui sont la profondeur p 3 4 ind = find([arbre.profondeur]==p); |
| 1 function ind = search_leaves(arbre) 2 % Fonction qui retourne les indices des feuilles de l'arbre 3 4 s = zeros(1,length(arbre)); 5 for i = 1:length(arbre) 6 s(i) = sum(arbre(i).suivant(:)); 7 end 8 ind = find(s |
This document was translated from LATEX by HEVEA.
 [cas déterministe]
[cas déterministe]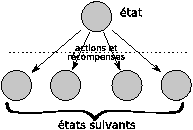
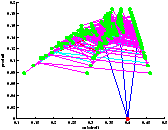
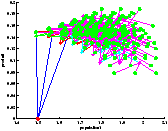 [exploration par UCT avec 50 lancements de trajectoire]
[exploration par UCT avec 50 lancements de trajectoire]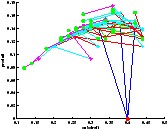
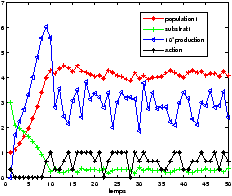
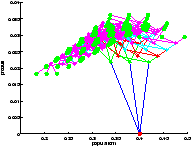
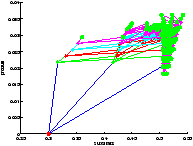
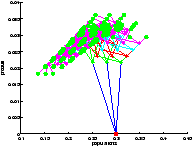
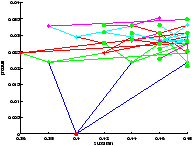
 [exploration UCT]
[exploration UCT]